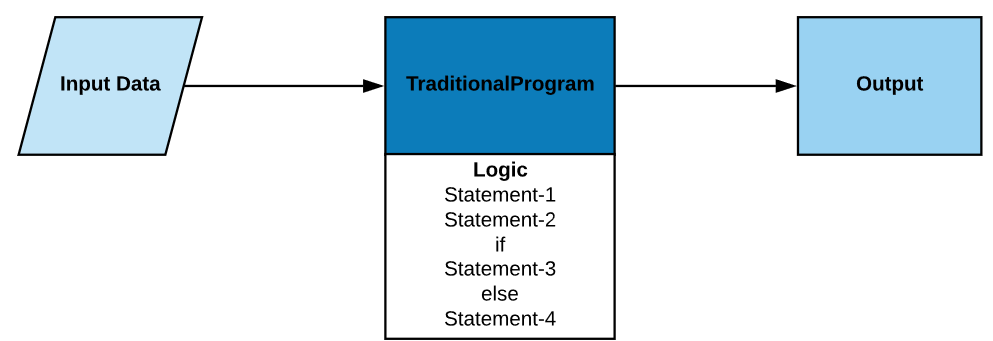
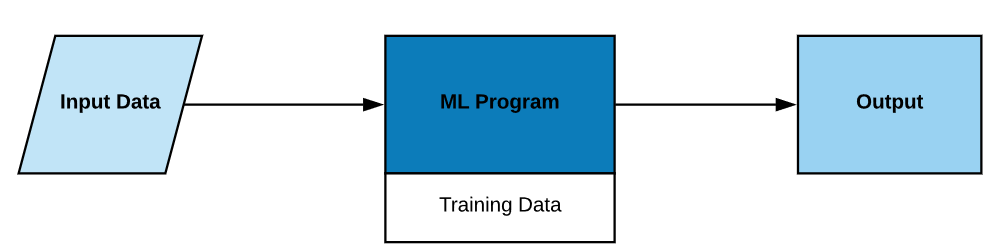
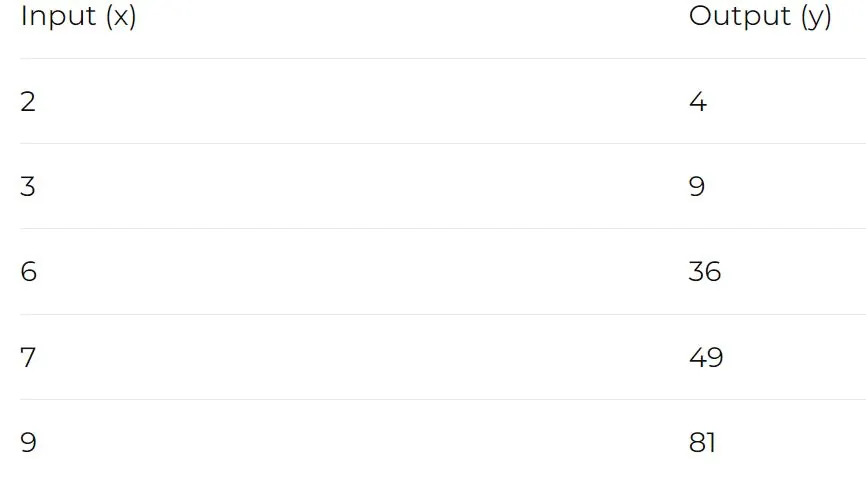
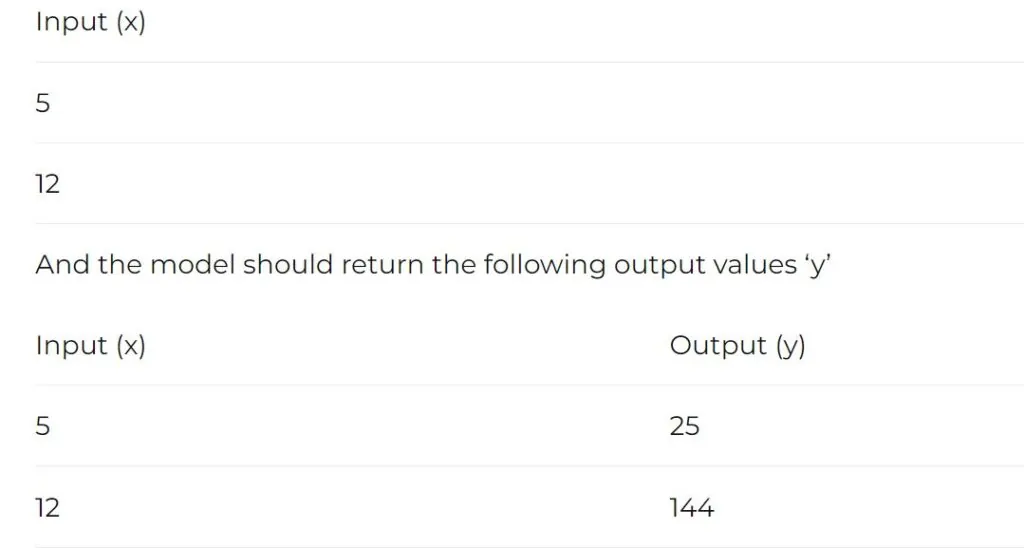
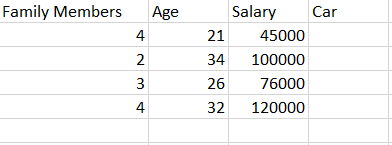
The input data is important for machine learning because your model is dependent on the data. The only thing the ML model gets as input is the dataset, and the accuracy of predictions made by the model is directly dependent on the quality of data you feed to the model. Just imagine a little kid, if the kid is grown up in a better environment, that kid will learn better and will make better decisions. Similarly, the ML model gets mature with time as you feed more and more data to it just like a kid gets mature with age and experience. According to some surveys, 70% time of an ML project is spent on gathering and preparing the dataset.
We at AlphaBOLD specialize in implementing innovative Machine learning solutions to help grow your business. Contact us; we will be more than happy to help you.