
How Energy Drink Manufacturers Use Machine Learning to Achieve Clean Actionable Data

Awais Aslam
Table of Contents
Introduction
Data is essential in the dynamic world of energy drinks. Consumer preferences shift rapidly, distributors handle countless product variations, and marketing campaigns run at breakneck speed. However, messy data from multiple sources often leaves manufacturers guessing instead of planning. This is where machine learning for data cleansing plays a critical role. It offers a scalable and automated way to consolidate disparate information into a single, trusted view.
This blog explores how an energy drink brand can tackle data quality issues using ML-based solutions. We provide technical insights into solving these challenges and outline guardrails for effectively auditing and maintaining data integrity.
Challenge: Diverse, Messy Data Streams
Energy drink manufacturers manage diverse data sources, each presenting unique challenges. Retail Point-of-Sale (POS) systems provide transaction details, including units sold, pricing, promotions, and timestamps. E-commerce & Direct-to-Consumer channels generate online orders and customer details. Loyalty & Marketing programs add complexity with data from promo codes, email interactions, and in-app engagements. Supplier & Production Logs capture ingredient costs, batch IDs, and yield rates. Additionally, Depletion Data tracks distributor-reported movement of products from warehouses.
These datasets hold valuable insights, but additional energy drink manufacturers’ data challenges are faced in maintaining data quality. For instance, inconsistent product naming conventions, such as “RevUp Tropical Storm,” “RevUp Trop Storm,” and “Tropical Storm by RevUp,” create confusion. Duplicate records, whether for distributors, retailers, or loyalty accounts, complicate analysis. Additionally, missing fields, such as item codes in depletion reports or discount amounts in POS data, lead to incomplete information. Varied formats & units, including differences in time zones, measurement units (ml vs. oz), and inconsistently coded promotions (e.g., “Promo20” vs. “PROMO_20”), further exacerbate the issue.
These data inconsistencies hinder inventory management, disrupt production planning, and derail marketing strategies for new product launches. However, leveraging machine learning for data cleansing or AI and ML for data cleansing can address these challenges effectively. By automating the identification and resolution of errors, ML-based solutions for data quality transform messy, fragmented information into clean, actionable data that drives results.
Do More with Data with Power BI and Machine Learning
Explore how our expertise in machine learning for data cleansing can tackle your data challenges and deliver clean and actionable data.
Request a DemoSolution: The ML-Driven Data Cleansing Pipeline
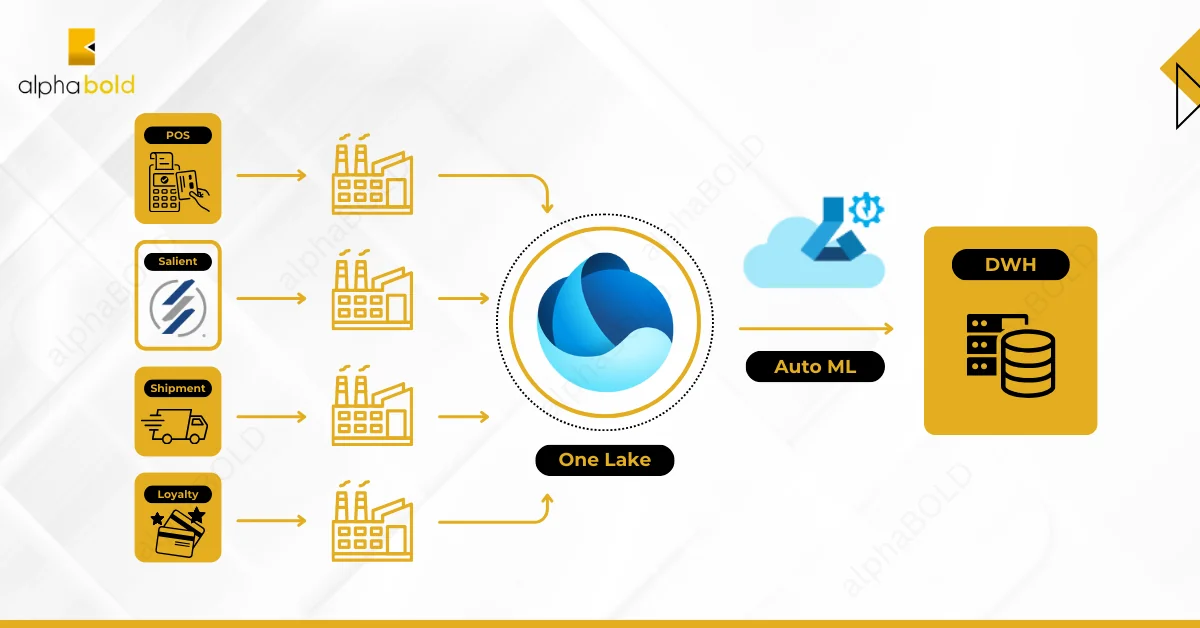
Step 1: Data Ingestion & Schema Alignment
The process begins with data lake ingestion and schema alignment, where all raw data — such as POS, e-commerce, and depletion logs — flows into a unified repository, Microsoft Fabric One Lake. During this phase, a “data dictionary” aligns field names (e.g., product_id, distributor_id, transaction_time) and standardizes data types across all sources. This standardization ensures that ML models and rulesets applied later work on consistent inputs.
Tools like Azure Data Factory or Fabric Data Factory orchestrate these data ingestion pipelines. During ingestion, they can run custom scripts or ML models and perform initial validations and transformations.
You may also like: The Value of Consulting Expertise in Power BI Implementations
Step 2: ML-Based Data Standardization
1. Natural Language Processing (NLP):
It uses the Azure Auto ML text classification approach by collecting variations of product names (e.g., “RevUp Trop Storm”) along with their standardized labels (e.g., “RevUp Tropical Storm”). Upload this labeled data into Azure ML and create an Automated ML experiment, mapping the text column to your input and the standardized name as the target. Azure ML automatically tries various NLP techniques (like embeddings or TF-IDF) and model architecture, ranks them by performance metrics (accuracy, F1-score), and selects the best solution. After training, deploy the top model as an inference endpoint, passing in new text strings to receive a predicted standard name; you can add confidence thresholding and manual review for low-certainty outputs.
2. Automated Unit Conversions:
Step 3: Entity Resolution for Deduplication
1. Gradient Boosting:
An entity resolution model compares fields (e.g., distributor name, address, phone number) to detect duplicates. For example, “XYZ Distributing” vs. “XYZ Distributors” might score high similarity on string metrics, geographic proximity, and more.
2. Scoring & Merging:
If the model’s confidence passes a certain threshold (e.g., 0.8), the two records are merged into a “golden record.” Borderline cases get flagged for manual review. Frameworks like Dedupe (Python library) combined with specialized ML algorithms can handle large-scale entity resolution. You often tune hyperparameters (like similarity thresholds) to reduce false matches.
Step 4: Intelligent Imputation of Missing Values
- Regression for Numerical Fields: Missing values in depletion data (e.g., inventory_on_hand) can be predicted using Random Forest or XGBoost. Key features might include store size, historical depletion trends, or seasonality patterns.
- Classification for Categorical Variables: For missing retailer types, a classification model (e.g., LightGBM) can infer likely categories based on store location, average transaction size, and other known fields.
- Confidence Threshold: If the predicted value’s confidence is low, the record is flagged manually for a data steward to review.
Explore our case study: Beverage Manufacturer Improves Operational Visibility and Taps New Market Opportunities
Key Takeaways for Energy Drink Manufacturers

- Embrace ML FOR Data Cleansing: Rule-based scripts alone can’t handle the scale or complexity of modern beverage data, especially critical depletion reports.
- Set Up Proper Guardrails: Periodic audits and real-time monitoring are essential for data integrity.
- Invest in Multi-Source Integration: Combine POS, e-commerce, and depletion data for a more holistic market view. Ensure consistent schemas and unit conversions.
- Put Humans in the Loop: Automation can eliminate most manual tasks, but human expertise is indispensable for refining models and making judgment calls.
Optimize your Data with AlphaBOLD’s ML-based Solutions
Consult AlphaBOLD to build automated, scalable data cleansing solutions for your business.
Request a DemoConclusion
For any energy drink manufacturer, the stakes have never been higher: consumer preferences change swiftly, distributors demand accurate forecasting, and competition is intense. Energy Drink Manufacturers could transform their chaotic data into a clean, unified asset by leveraging an ML-based data cleansing pipeline and reinforcing it with robust guardrails.
Explore Recent Blog Posts






