In this blog, we will perform a deep dive into the details of Vertipaq Engine. We will figure out how it stores data, the best ways to model our data warehouse, and the most practical and helpful compression techniques used to obtain better performance and efficiency from our Tabular data model.
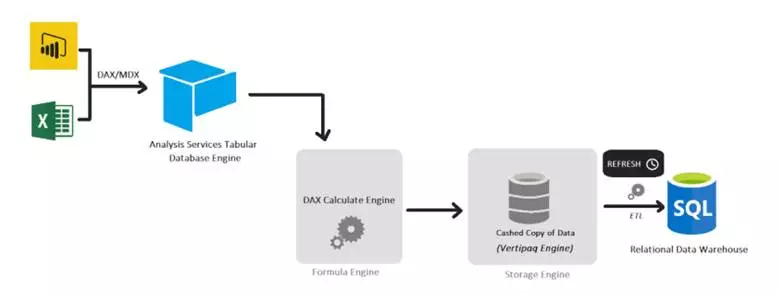
Whenever data from different source tables is loaded into memory, it always undergoes processing. Requests are sent to the Tabular database either using MDX or DAX queries. These queries are then processed using two calculation engines.
Formula Engine (FE): Formula Engine processes the request, transforms it into query plans, and finally executes those plans.
Storage Engine (SE): Storage Engine stores the data, performs all the calculations, and answers all the Formula Engine’s requests.Data can be stored in the import mode, also known as in-memory or Vertipaq, or in Direct Query, depending on the mode we chose for building our model. But in this blog, we are going to focus on the Vertipaq engine.
Vertipaq Engine
Vertipaq is a columnar database that runs on top of power BI and power pivot. The database stores our data, transforms it, and helps us provide a fast model and improved performance.
In a columnar database, data is organized in column format, which is a great way to optimize vertical scanning. When data is stored in a columnar database, each column has its own data structure, and it is physically separated from the others so that it can be compressed more effectively. Within a column, there is more redundancy than within a row, so data can be compressed to a greater degree. This requires less IO to fetch data into memory, and in return, it speeds up the query response time.
Vertipaq Compressions
While working with big data, one faces many real-world problems like complex queries, huge data, increased processing time, and much more. All these issues can be resolved with the help of Vertipaq compressions.
When Vertipaq stores each column in a separate data structure, the engine performs some compressions and encoding to reduce our data model’s memory usage. This helps us improve all the performance issues as it avoids the scanning of useless data.
When we import data into Power Bi, the following are the Vertipaq engine techniques to provide us with a fast and optimized model.
Dictionary Encoding
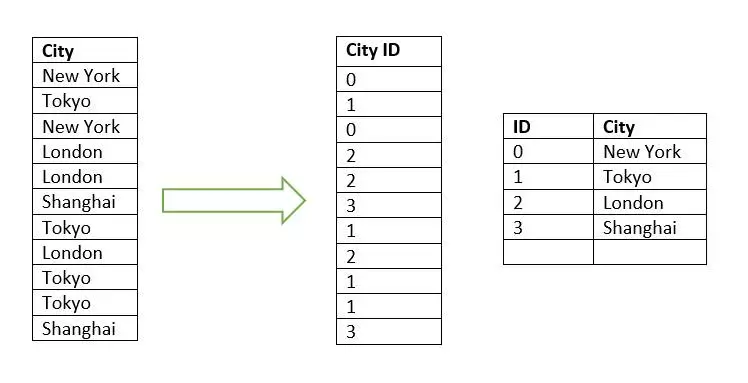
Dictionary Encoding is a technique used by Vertipaq to compress text by reducing the number of bits required to store a column. It helps eliminate the storage of duplicate values in a column, reducing the overall memory & disk space required to hold the data. In this, Vertipaq gets all the distinct values from the column and builds a dictionary containing those values. It then replaces all the values of the column with integers which are basically indexes to the dictionary.
Vertipaq is datatype independent. It can use integers, strings, or floating points to represent data as all these will be dictionary encoded, providing the same performance and efficiency both in terms of storage and speed.
As we can see in the following table, we have a City column containing values in a string. After getting all the unique values, Vertipaq creates a dictionary, giving each city its own id. All the values in the column are replaced by these City ids directing us to the actual City values stored in the dictionary.
This shows that the dictionary’s size is very small compared to the column’s actual size, so much less space/memory is required to store it, allocating RAM a lot more space to store more data. Moreover, it increases the processing speed as scanning becomes quick, giving us fast queries and great performance. Further Reading: How to Integrate Multiple Data Sources in Power BI
Ready to Empower your Business with Data-Driven Insights?
Discover how Power BI can revolutionize your data analysis and reporting. AlphaBOLD's Power BI experts are here to help you harness the full potential of your data.
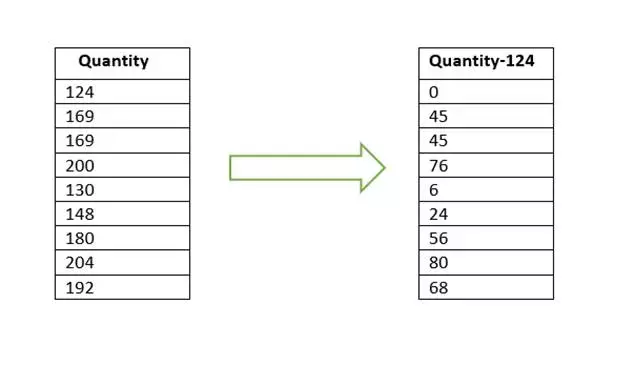
Value Encoding is another technique used by Vertipaq to compress data and reduce memory usage. This technique is only used for integers as it involves mathematical transformations, so it cannot be applied to strings or other datatypes.
In this technique, Vertipaq reduces the number of bits required to store each value. The engine goes through the data set and finds the best way to minimize the numbers.
In the following example, we can see a Quantity column having 3-digit values. Going through the dataset, Vertipaq chooses the minimum value, i.e., 124, and subtracts it from all the values in column. This gives us data that contains a range from 0-80. Minimizing the maximum value from 204 to 80 requires fewer bits to store the data than the actual column.
Whenever we need to see the column’s data, it will apply the transformations again in the opposite direction and provide us with the actual values of the column. You can see that how much space is saved by this value encoding.
Run Length Encoding
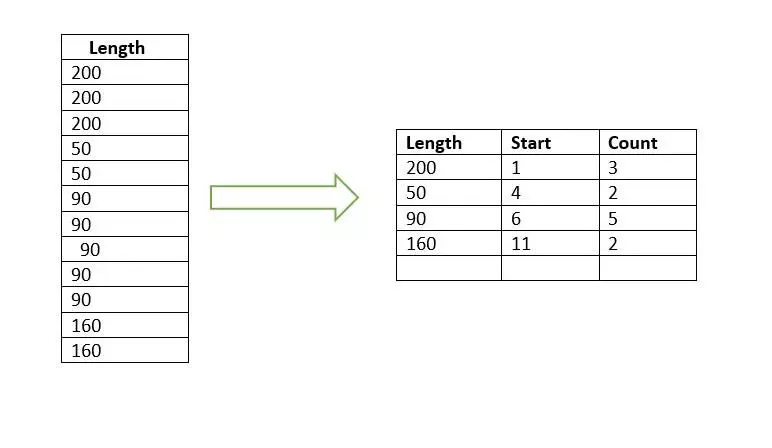
Run Length Encoding is another Vertipaq technique to reduce our data size by avoiding all the repeated values. It always takes place after Value and Dictionary Encoding.
There might be some columns in our dataset where we have the same values repeatedly repeating for many rows, hence increasing the data size and memory usage. By eliminating all the duplicate values, we can compress our data to a great extent, and this is what run-length encoding does.
Here we can see an example for better understanding.
In this example, we can see that all the duplicate values are considered and stored only once in the table, along with their starting point and count. In reality, the Start column is not stored by Vertipaq as it is fast enough to calculate it using previous values of count.
It works great when we have data, as discussed above in the example. But in some cases, we might have data that frequently changes. In that case, applying the RLE algorithm would not be an optimal solution. When data is constantly changing, storing the count of each value separately will result in a larger RLE column compared to the actual column. So, in such a case, RLE is not a suitable approach.
In this article, we have discussed the internal architecture of a Tabular database engine. We have emphasized how the Vertipaq Engine helps us get optimized data and fast model using its various compression techniques. We have learned about some basic types of encoding in detail used by Vertipaq to reduce the size of a data model and help us achieve great performance and efficiency.