In my previous blog, we created an Azure Data Factory instance and discussed its benefits. We discussed how Azure Data Factory allows users to transform their raw data into actionable insights. In this blog, I shall introduce you to major Azure Data Factory components for this process. So, let us start exploring the Data Factory components.
The following are Azure Data Factory components that I shall be covering. These components transform your source data and make it consumable for the end product.
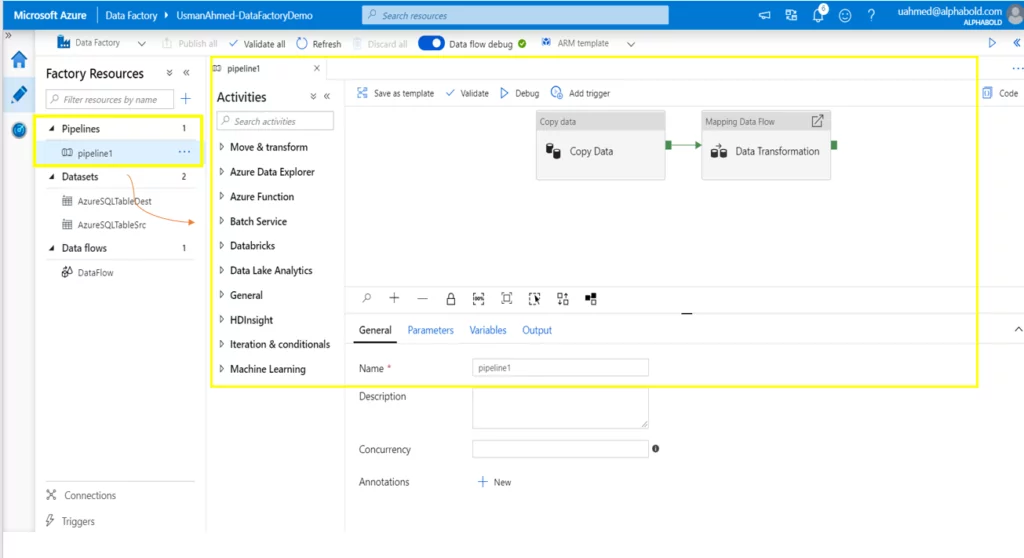
Pipelines
Activities
Dataflows
Datasets
Linked Services
Integration Runtimes
Triggers
Please Note: You need to have created a data factory instance to follow this blog. If you do not know how to create a data factory instance, please refer to the following blog:
Introduction to Azure Data Factory Components
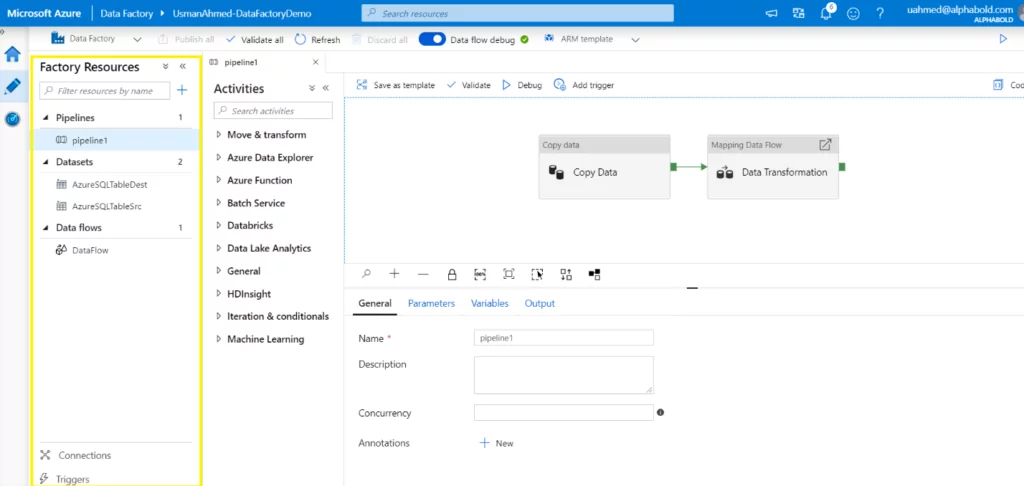
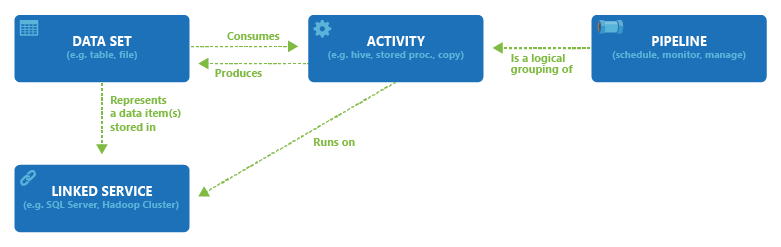
To understand the Azure Data Factory components, we shall look at an example comprising a pipeline, two datasets, and one dataflow, as shown below.
Pipelines
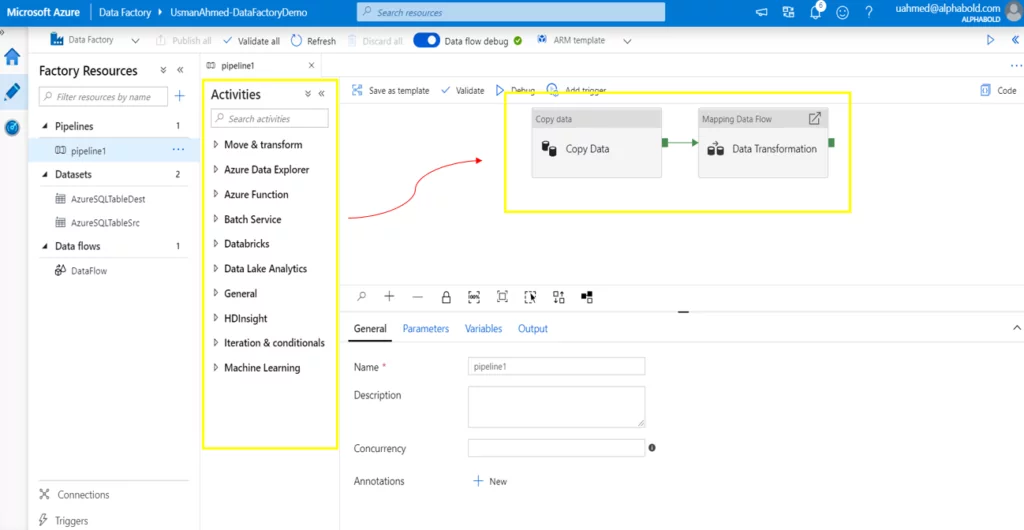
A pipeline is defined as a logical group of activities to perform a piece of work. A Data Factory can comprise multiple pipelines, each with multiple activities. The activities inside the pipelines can be structured to run sequentially or in parallel, depending on your needs. The pipeline allows users to manage and schedule multiple activities together easily.
Activities are processing steps that perform each task. This Azure data factory component supports data movement, data transformation, and control activities. The activities can be executed in both a sequential and parallel manner.
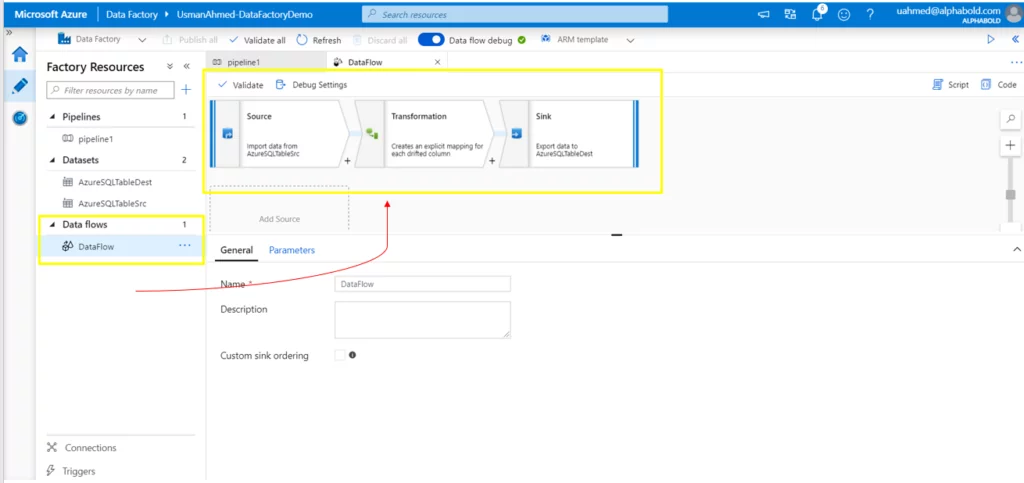
Data Flows
These special activities allow data engineers to develop a data transformation logic visually without writing code. They are executed inside the Azure Data Factory pipeline on the Azure Databricks cluster for scaled-out processing using Spark. Azure Data Factory controls all the data flow execution and code translation. It handles a large amount of data with ease.
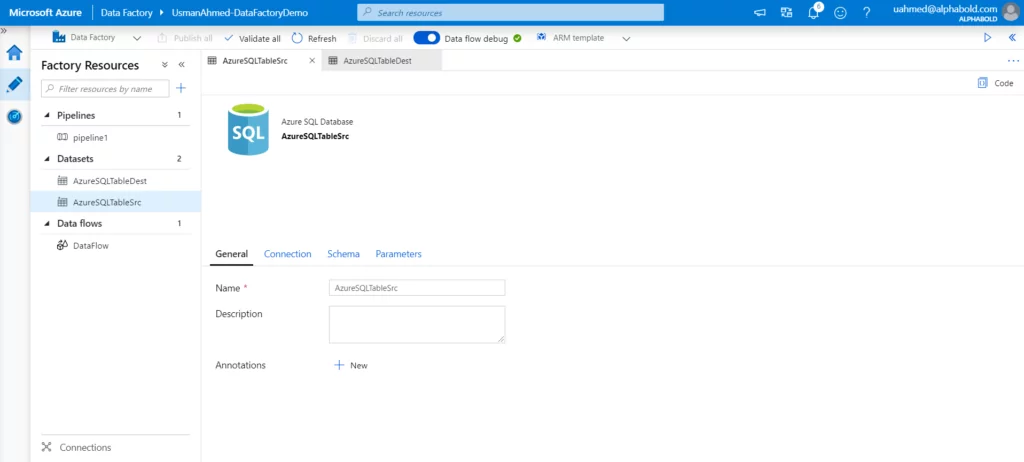
You need to specify the data configuration settings for the movement or transformation of data. A dataset can comprise a database table or file name, folder structure, etc. Moreover, every data set refers to a linked service.
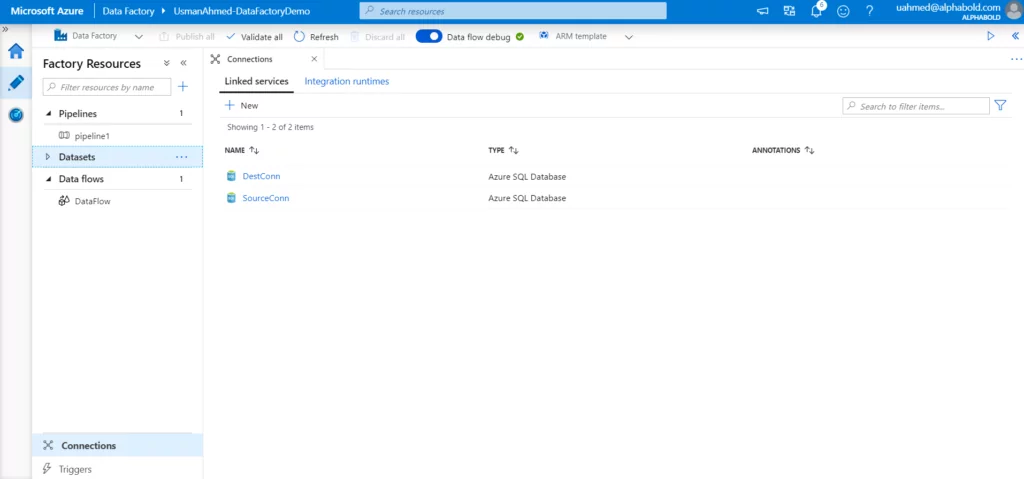
Linked Services
As a pre-requisite step, before connecting to a data source (e.g. SQL Server) we create a connection string. The Linked Services act like connection strings in a SQL server. They contain information about data sources & services. The requesting identity connects to a data source using this linked service/connection string.
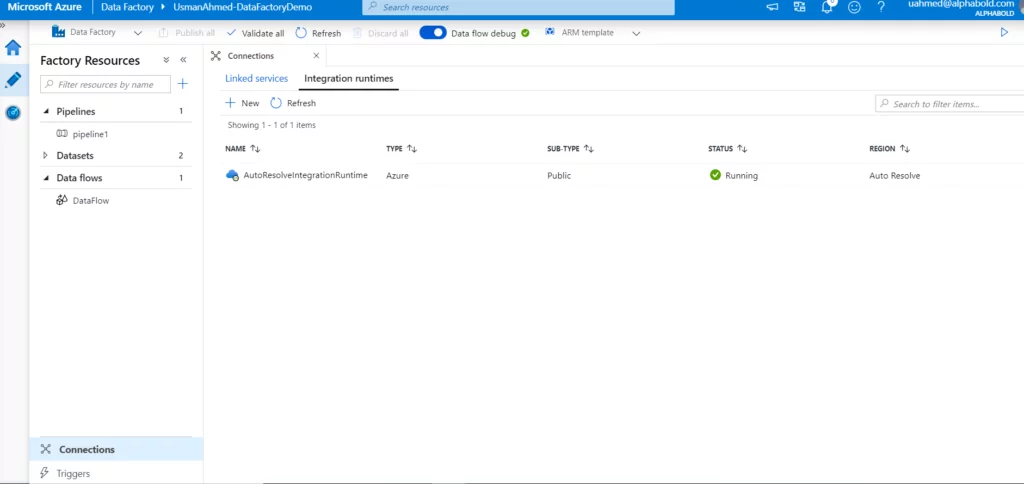
Integration Runtimes
Integration Runtimes provide a compute infrastructure on which activities can be executed. You can choose to create them from three types:
Azure IR: This service provides a fully managed, serverless compute in Azure. All the movement and transformation of data is done in the cloud data stores.
Self-hosted IR: This service is needed to manage activities between cloud data stores and a data store residing in a private network.
Azure-SSIS IR: This is primarily required to execute native SSIS packages.
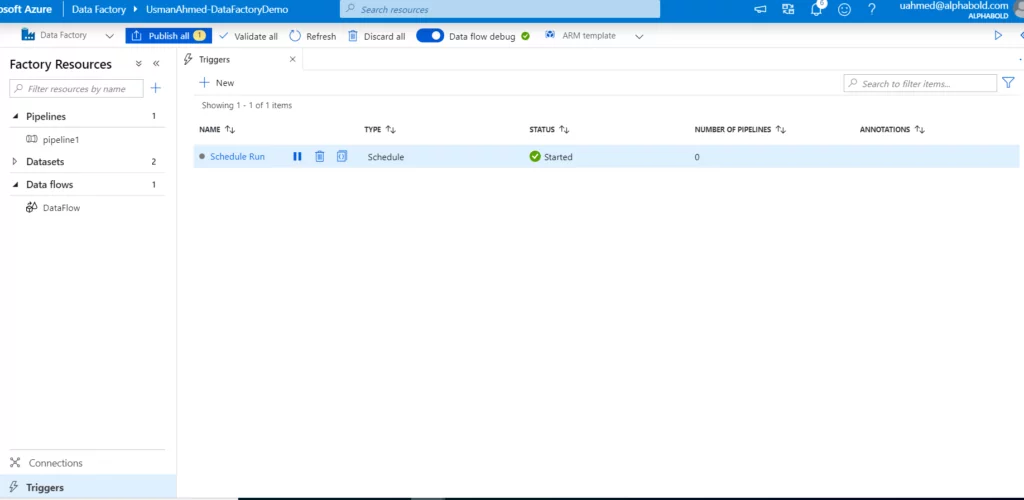
Triggers
They are needed to execute your pipeline without any manual intervention at a pre-defined schedule. We can set the configuration settings like start/end date, execution frequency, time to execute, etc.
Unlock Advanced Data Solutions with Azure!
Unlock the full capabilities of your data with Azure Data Factory's advanced solutions. Partner with AlphaBOLD for strategic insights and smarter data solutions.
In this blog, we went over the different components of Azure Data Factory. The diagram below represents the relationship between the different components of the Azure Data Factory at a high level, as explained on the official Microsoft website.
Conclusively, pipelines are created to execute multiple activities. The input and output format of the dataset is defined for the activities involved in data transformation or data movement. Next, data sources or services connect with the assistance of linked services. To facilitate the infrastructure and execution location of the activities, we use integration runtimes. When the creation of the pipeline and the activities inside it are complete, we automatically add triggers to execute it at a specific time or event.
Now that we have theoretically understood the Azure Data Factory components, we can make things HAPPEN!
Stay tuned for the next blog in which we shall be using these components. Also, please type your questions and queries in the comment box below!
If you have any questions or queries, please contact us!